2023.06.27
AIの力で英語ネイティブスピーカーになってみたい Part2
こんにちは。AaaS Tech Labの小山田です。
最近、so-vits-svc(SoftVC VITS Singing Voice Conversion[1])やRVC(Retrieval-based Voice Changer[2])など、声質変換系の技術が話題になっているかと思います。自分で用意した音声データ活用し、従来よりも容易にfine-tuningなどを行うことが可能となっていたり、WebUIが用意されているなどの点から、非エンジニア/データサイエンティストの方にも利用が広まっている印象です。
そこで今回は以前AaaS Tech Labのcolumn記事として公開した「AIの力で英語ネイティブスピーカーになってみたい[3]」の続編という形で、RVCを活用し、自分の声で話した流暢な英語音声を生成できるか挑戦したいと思います。
ここで、下図はPart1の記事でも掲載したものですが、RVCによる取り組みはBetterに相当する処理かと思います。ただし、RVCではVCTKコーパス[4]を学習したモデルがオープンソースで公開されているので、基本的にはターゲット話者(ここでは小山田)の音声データのみ用意すれば学習等を行うことができます。

RVCについて
RVCは特に論文などの形で公開された手法ではなく、github上でオープンソースとして公開されているものです。
こういった要因もあるのか、RVCのUI等に関する使い方の解説記事は多くあっても、内部のアルゴリズム等に関する紹介/解説はほとんど見つけることができません。
よって、下記で少し内部ロジックについて触れていきますが、あくまで公開されているコードを読むなどした現状の理解である点にご注意ください。
こういった要因もあるのか、RVCのUI等に関する使い方の解説記事は多くあっても、内部のアルゴリズム等に関する紹介/解説はほとんど見つけることができません。
よって、下記で少し内部ロジックについて触れていきますが、あくまで公開されているコードを読むなどした現状の理解である点にご注意ください。
RVCは基本的に、Part1の記事でも簡単に紹介したVITS[5]を派生させたようなモデルかと思います。
※VITSの解説はこちら[6]の記事が分かりやすいかもしれません。
そこで、VITSと比較する形でRVCの構造を考えてみたいと思います。まず2つのモデル構造を簡単に図示してみましょう。
※RVCではf0(声の高さ)を加味するアプローチも存在しますが、ここでは簡単の為、f0を加味しないケースについて考えます。
※VITSの解説はこちら[6]の記事が分かりやすいかもしれません。
そこで、VITSと比較する形でRVCの構造を考えてみたいと思います。まず2つのモデル構造を簡単に図示してみましょう。
※RVCではf0(声の高さ)を加味するアプローチも存在しますが、ここでは簡単の為、f0を加味しないケースについて考えます。
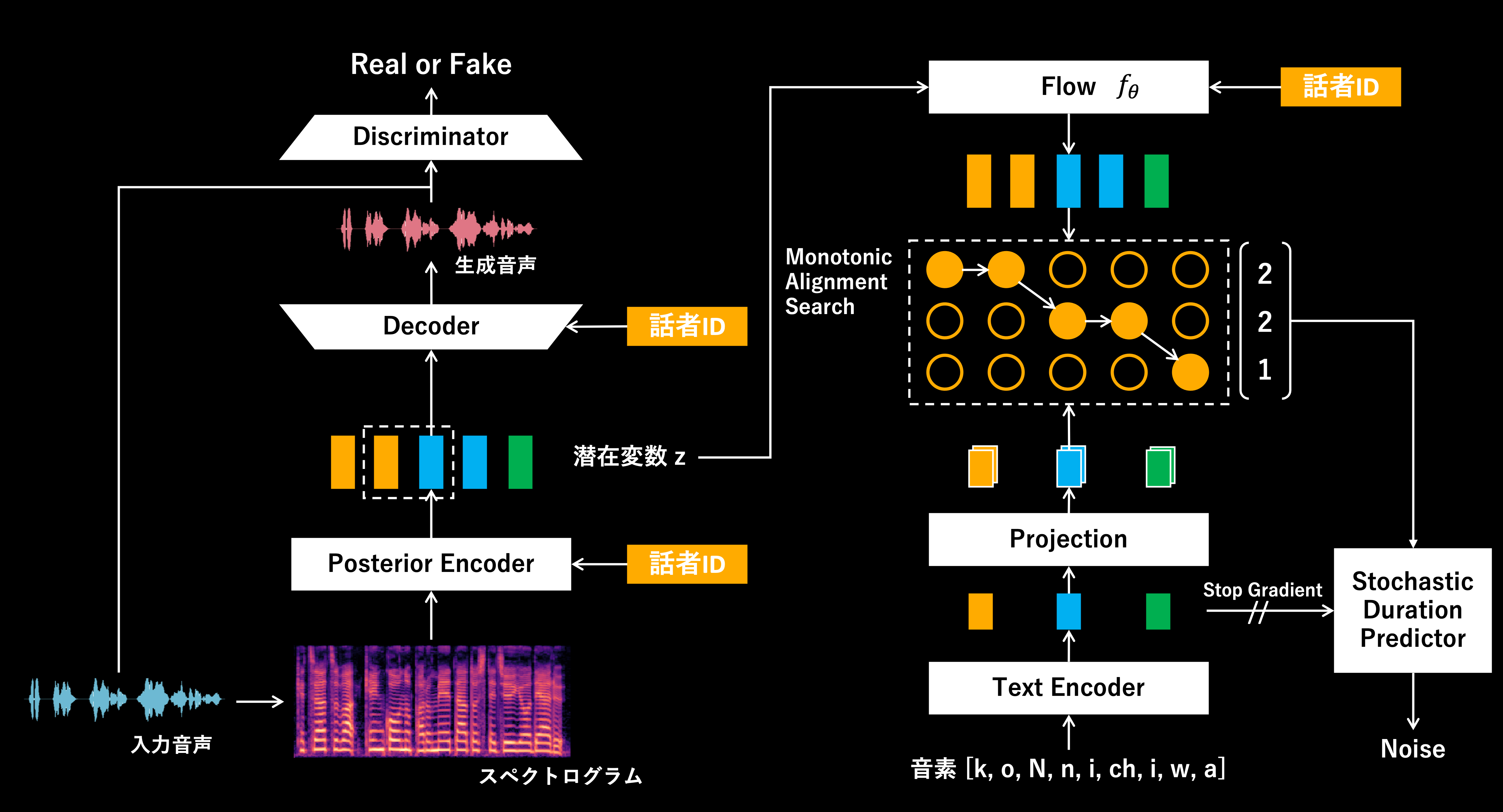
VITSの構造
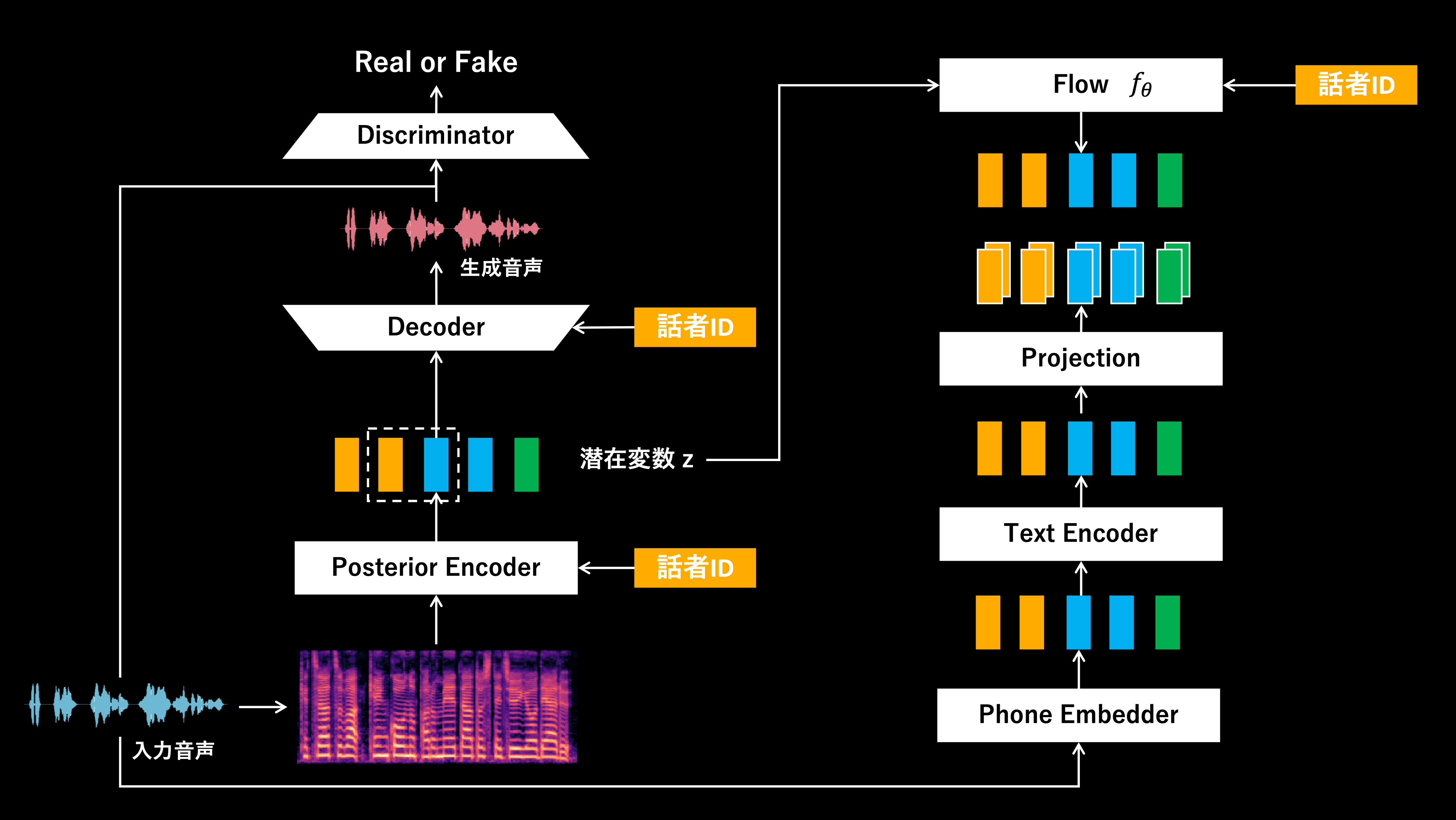
RVCの構造
上記、2つのモデル構造を見比べると大きな違いは、音素(テキスト情報)を入力とするか否かかと思います。
VITSはTTS(Text to Speech; テキスト音声合成)およびVC(Voice Conversion; 声質変換)が可能なモデルであり、音素情報を処理する構造が必要です。
一方で、RVCはVCに特化したモデルのため、音素情報を処理する構造は撤廃されています。その代わり、Phone Embedderで入力音声から得られる特徴量を発話内容を表現した特徴量として活用しています。ここで、Phone EmbedderにはHuBERT[7]やContentVec[8]が用いられます。HuBERTなどは音声認識にも応用されるモデルであるため、音声から発話内容に関する言語情報を含む特徴量が抽出できていると考えられます。
VITSはTTS(Text to Speech; テキスト音声合成)およびVC(Voice Conversion; 声質変換)が可能なモデルであり、音素情報を処理する構造が必要です。
一方で、RVCはVCに特化したモデルのため、音素情報を処理する構造は撤廃されています。その代わり、Phone Embedderで入力音声から得られる特徴量を発話内容を表現した特徴量として活用しています。ここで、Phone EmbedderにはHuBERT[7]やContentVec[8]が用いられます。HuBERTなどは音声認識にも応用されるモデルであるため、音声から発話内容に関する言語情報を含む特徴量が抽出できていると考えられます。
ちなみに、RVCでは音素を入力としない(TTSを取り扱わない)ことにより、VITSには存在する「Monotonic Alignment Search」や「Stochastic Duration Predictor」などの構造も撤廃されています。
VITSでは、音素とスペクトログラムから潜在変数zが従う分布を推定し、それぞれから得られた分布の分布間距離を最小化するような学習を行います。このとき、音素の系列長とスペクトログラムの系列長が異なる為、上述した構造が必要でした。逆にいうと、その構造があることで音素から発話長(ある音素をどのくらいの長さで発話するか)を推定できるようになっていました。
一方で、RVCの場合、Phone Embedderから得られる発話内容に関する特徴量も、スペクトログラムも、入力される音声波形から抽出されるので系列長を揃えることができます。よって、アライメント処理などを伴わない形で、2つの特徴量から得られる分布間距離を最小化するような学習が可能です。こちらも逆にいうと、RVCでは発話長の変換は考えておらず、入力音声と同じスピードやテンポで話した音声が変換結果として得られるようになっています。
VITSでは、音素とスペクトログラムから潜在変数zが従う分布を推定し、それぞれから得られた分布の分布間距離を最小化するような学習を行います。このとき、音素の系列長とスペクトログラムの系列長が異なる為、上述した構造が必要でした。逆にいうと、その構造があることで音素から発話長(ある音素をどのくらいの長さで発話するか)を推定できるようになっていました。
一方で、RVCの場合、Phone Embedderから得られる発話内容に関する特徴量も、スペクトログラムも、入力される音声波形から抽出されるので系列長を揃えることができます。よって、アライメント処理などを伴わない形で、2つの特徴量から得られる分布間距離を最小化するような学習が可能です。こちらも逆にいうと、RVCでは発話長の変換は考えておらず、入力音声と同じスピードやテンポで話した音声が変換結果として得られるようになっています。
RVCによる声質変換
では続いて、RVCとVITSによるVCにおける処理の違いについて考えます。
ここでも処理の流れも図示して考えていきましょう。
ここでも処理の流れも図示して考えていきましょう。
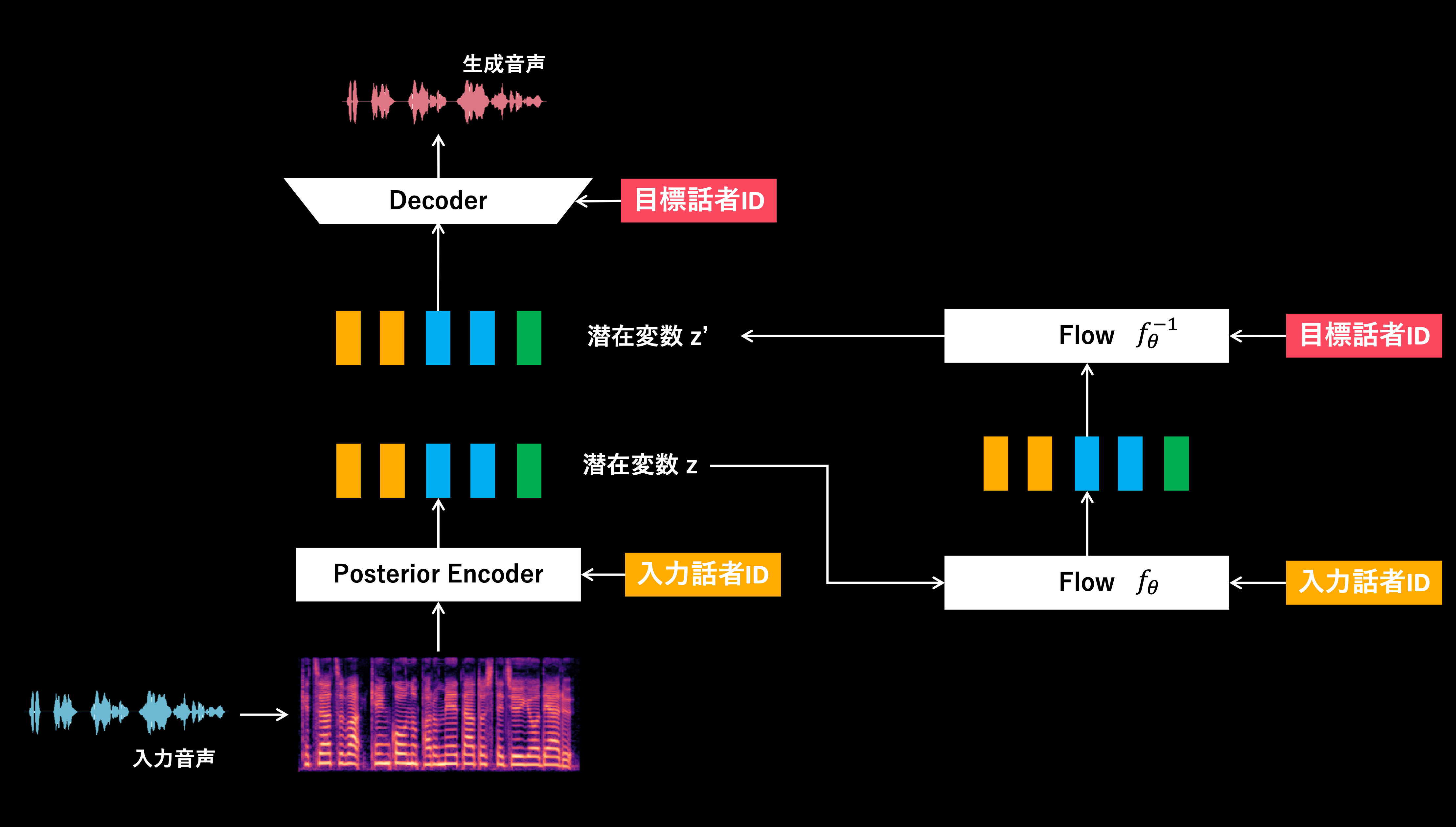
VITSによる処理構造
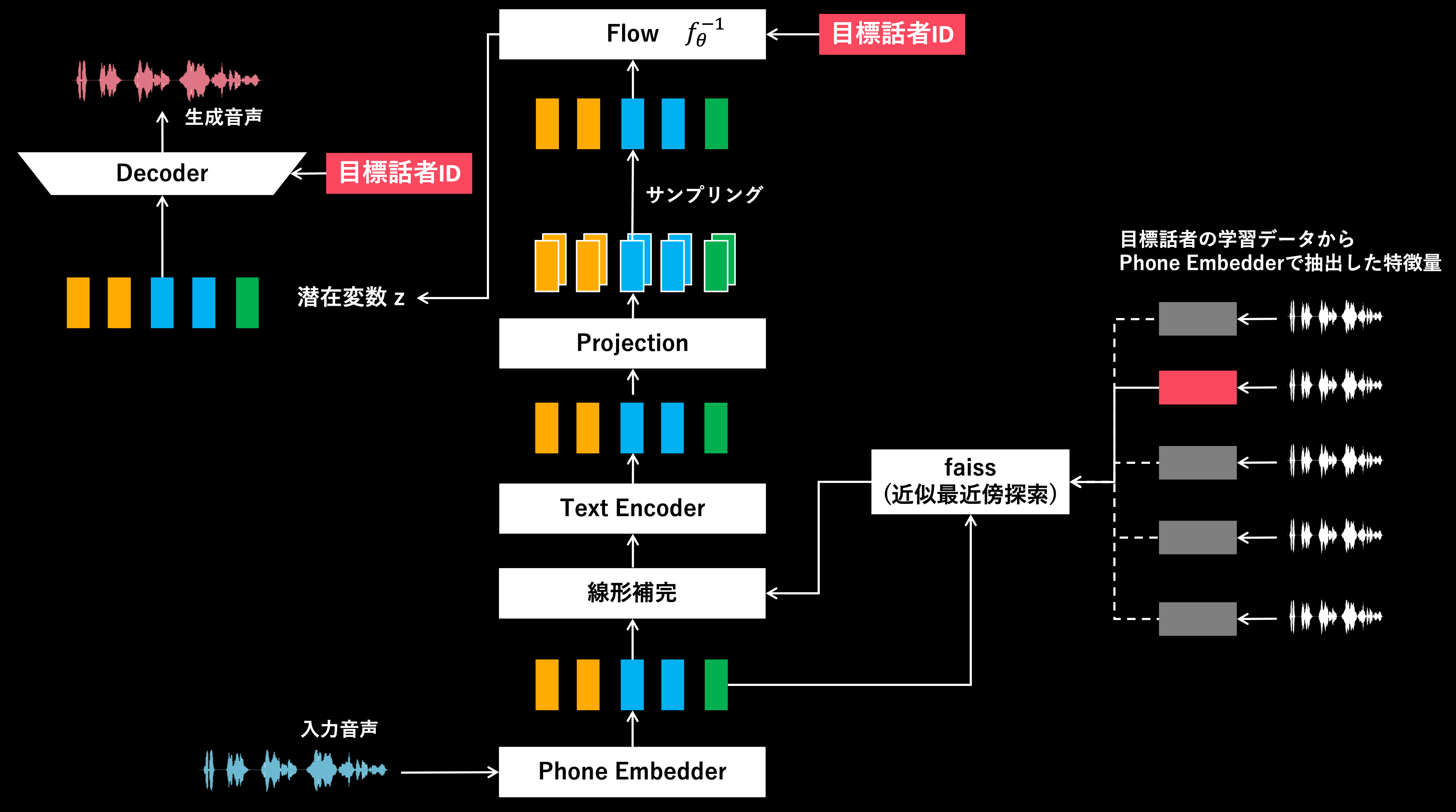
RVCによる処理構造
2つの構造を比較すると大きく異なる点は、スペクトログラムを直接の入力とした処理を行うか否かかと思います。
VITSの場合は、入力音声からスペクトログラムを抽出し、それを入力話者のID情報と一緒に埋め込みます。そこで得られた埋め込み表現を目標話者のID情報と一緒にデコードすることで、VCを行っているイメージなるかと思います。
一方RVCでは、入力音声からPhone Embedderで発話内容に関する特徴量を抽出し埋め込み。それを目標話者IDと一緒にデコードすることで、目標話者のような音声を生成します。つまり、VITSにおけるTTSに近いような処理の流れでVCを行っていると考えることもできるかと思います。
またRVCの大きな特徴として、入力音声からPhone Embedderで得られた特徴量について、目標話者の学習データから事前に抽出された特徴量と線形補完を行います。この時、入力された音声と最も近い(発話内容が似ている)特徴量を「検索」し線形補完を行います。この「検索」(==Retrieval)処理が行われることがRVC(Retrieval-based Voice Changer)という名前の由来かと思います。
ちなみになぜこういった処理を行っているか考えると、ここまで分かりやすさの為Phone Embedderで得られる特徴量を「発話内容に関する特徴量」などと表現してきました。しかし、実際には発話内容などの言語情報だけでなく、話者性(誰っぽいか)に関する情報もある程度含まれてしまっていると考えられます。おそらくこの影響で、入力音声によっては入力話者の話者性を除去しきれず、目標話者にあまり似ていない音声が変換結果として得られることもあるのだと思います。これを防ぐために、目標話者が入力音声と近い内容を発話したであろう特徴量を検索し線形補完することで、発話内容を変えることなく、Phone Embedderで得られる特徴量を目標話者へと事前に近づけようとしているのだと考えています。
VITSの場合は、入力音声からスペクトログラムを抽出し、それを入力話者のID情報と一緒に埋め込みます。そこで得られた埋め込み表現を目標話者のID情報と一緒にデコードすることで、VCを行っているイメージなるかと思います。
一方RVCでは、入力音声からPhone Embedderで発話内容に関する特徴量を抽出し埋め込み。それを目標話者IDと一緒にデコードすることで、目標話者のような音声を生成します。つまり、VITSにおけるTTSに近いような処理の流れでVCを行っていると考えることもできるかと思います。
またRVCの大きな特徴として、入力音声からPhone Embedderで得られた特徴量について、目標話者の学習データから事前に抽出された特徴量と線形補完を行います。この時、入力された音声と最も近い(発話内容が似ている)特徴量を「検索」し線形補完を行います。この「検索」(==Retrieval)処理が行われることがRVC(Retrieval-based Voice Changer)という名前の由来かと思います。
ちなみになぜこういった処理を行っているか考えると、ここまで分かりやすさの為Phone Embedderで得られる特徴量を「発話内容に関する特徴量」などと表現してきました。しかし、実際には発話内容などの言語情報だけでなく、話者性(誰っぽいか)に関する情報もある程度含まれてしまっていると考えられます。おそらくこの影響で、入力音声によっては入力話者の話者性を除去しきれず、目標話者にあまり似ていない音声が変換結果として得られることもあるのだと思います。これを防ぐために、目標話者が入力音声と近い内容を発話したであろう特徴量を検索し線形補完することで、発話内容を変えることなく、Phone Embedderで得られる特徴量を目標話者へと事前に近づけようとしているのだと考えています。
RVCのメリット
ここまではRVCの構造や処理内容について考えてきました。
では、実際に利用する側としては、何が嬉しいのでしょうか?
ここもあくまでVITSとRVCでの比較という形で考えてみたいと思います。(so-vits-svcもVITSをベースとした構造であり、下記と同じようなメリットがあるかもしれません。)
個人的には、大きく「学習データを用意しやすい」、「入力音声について汎用性が高い」という2点かと思っています。
では、実際に利用する側としては、何が嬉しいのでしょうか?
ここもあくまでVITSとRVCでの比較という形で考えてみたいと思います。(so-vits-svcもVITSをベースとした構造であり、下記と同じようなメリットがあるかもしれません。)
個人的には、大きく「学習データを用意しやすい」、「入力音声について汎用性が高い」という2点かと思っています。
まず「学習データを用意しやすい」という点を考えます。
VITSでは学習用データとして、テキストと音声のペアデータを用意する必要がありました。一方でRVCの場合は音声データさえあれば学習が可能です。例えば、自分がどこかで講演した時の音声を収録しておけば、文字起こしなどをすることなく学習に使えるわけです。音声に対応したテキストデータを必要としない点は学習データの準備におけるコストを非常に下げていると思います。
VITSでは学習用データとして、テキストと音声のペアデータを用意する必要がありました。一方でRVCの場合は音声データさえあれば学習が可能です。例えば、自分がどこかで講演した時の音声を収録しておけば、文字起こしなどをすることなく学習に使えるわけです。音声に対応したテキストデータを必要としない点は学習データの準備におけるコストを非常に下げていると思います。
続いて、「入力音声について汎用性が高い」について考えてみます。
VITSによるVCを行う場合、入力音声に対応した話者IDを与える必要がありました。つまり、目標となる話者だけでなく、入力話者のデータについても学習する必要があったわけです。(もちろん、入力話者IDとして適当なIDを割り当てれば動作はしますが、あまり良い結果にはならないと考えています。)
一方RVCでは、入力音声に関する話者IDは必要なく、入力と近い内容を発話したであろう目標話者の特徴量と線形補完が行うなどにより、少なくとも原理上は任意の話者の音声を入力とできるようになっている思います。もちろん、実際には入力音声によってうまく変換できないケースもあるはずですが。
VITSによるVCを行う場合、入力音声に対応した話者IDを与える必要がありました。つまり、目標となる話者だけでなく、入力話者のデータについても学習する必要があったわけです。(もちろん、入力話者IDとして適当なIDを割り当てれば動作はしますが、あまり良い結果にはならないと考えています。)
一方RVCでは、入力音声に関する話者IDは必要なく、入力と近い内容を発話したであろう目標話者の特徴量と線形補完が行うなどにより、少なくとも原理上は任意の話者の音声を入力とできるようになっている思います。もちろん、実際には入力音声によってうまく変換できないケースもあるはずですが。
RVCによる変換結果
では、実際に自分の声を学習させたRVCを使って、ネイティブスピーカーのように発話できるのか変換結果を見ていきたいと思います。
今回はITAコーパス[9]の全424文を読み上げ、自分の音声データを用意しました。
また、RVCはいくつか異なるソースコードが公開されていますが、今回は「rvc-webui[10]」を使用しています。
今回はITAコーパス[9]の全424文を読み上げ、自分の音声データを用意しました。
また、RVCはいくつか異なるソースコードが公開されていますが、今回は「rvc-webui[10]」を使用しています。
さらに今回は事前学習済みモデルを変えて、下記の3パターンを試してみました。
今回は簡単の為、下記の名称で各実験設定を呼称します。
今回は簡単の為、下記の名称で各実験設定を呼称します。
- cvec
- Phone Embedder : ContentVec
- Generator / Discriminator : rvc-webuiのデフォルトモデル
- hbj
- Phone Embedder : HuBERT (rinna/japanese-hubert-base[11])
- Generator / Discriminator : rvc-webuiのデフォルトモデル
- hbj_nadare
いずれの実験でも学習は、バッチサイズ64、epoch数100で統一しました。
(ここは、本当は事前学習済みモデルなど次第で変更すると良いかもしれません。)
(ここは、本当は事前学習済みモデルなど次第で変更すると良いかもしれません。)
では変換結果を聞いてみたいと思います。まずPart 1でも掲載しましたが、小山田の音声サンプルは下記です。
次に、英語音声を小山田っぽくRVCで変換した音声です。
入力音声は英語音声が生成可能なTTSで作成した音声です。
入力音声は英語音声が生成可能なTTSで作成した音声です。
| 入力音声 | cvecによる変換 | hbjによる変換 | hbj_nadareによる変換 |
|---|---|---|---|
| Ivy.mp3 | |||
| Joey.mp3 | |||
| Matthew.mp3 |
いかがでしょうか?
個人的にはPhone Embedder にHuBERTを活用した方が、発音が明瞭に聞こえる気がします。逆に、ContentVecを使った方が、自分に近い声のような気がしました。
といっても自己評価だけでは、自分の声に似ているかの判断が難しいと思ったので、AaaS Tech Labのメンバーにも上記音声サンプルを聴いてもらい、類似性(変換結果が小山田の声に似ているか)と品質(ノイズ等が少なく聞きやすい音声か)の2観点で評価してもらいました。
結果としては、類似性ではhbjが最も評価が高く、cvecが最も評価がイマイチでした。品質については、hbjが最も評価が高く、hbj_nadareの評価があまり良くないという結果になりました。
(おそらく)rvc-webuiでデフォルトとなっているGenerator / Discriminatorは、英語音声で学習されたContentVecをPhoneEmbedderに使用した状況でVCTKコーパスを使い学習されているはずです。hbj_nadareでは、そのGenerator / Discriminatorを、日本語データで学習されたHuBERT(rinna/japanese-hubert-base)をPhoneEmbedderにし、finetuningされている模様です。
hbj_nadareの結果が少し悪く見えてしまっている原因は、そもそも日本語音声の変換向けにモデルがチューニングされている可能性、および既にfinetuningされたものを今回さらにfinetuningしたわけなので少し過学習気味になり、ボコーダー感のあるノイズが乗ってしまった可能性が考えられます。Epoch数を減らし、日本語音声を取り扱うことで結果が変わる可能性がある点にはご注意下さい。
個人的にはPhone Embedder にHuBERTを活用した方が、発音が明瞭に聞こえる気がします。逆に、ContentVecを使った方が、自分に近い声のような気がしました。
といっても自己評価だけでは、自分の声に似ているかの判断が難しいと思ったので、AaaS Tech Labのメンバーにも上記音声サンプルを聴いてもらい、類似性(変換結果が小山田の声に似ているか)と品質(ノイズ等が少なく聞きやすい音声か)の2観点で評価してもらいました。
結果としては、類似性ではhbjが最も評価が高く、cvecが最も評価がイマイチでした。品質については、hbjが最も評価が高く、hbj_nadareの評価があまり良くないという結果になりました。
(おそらく)rvc-webuiでデフォルトとなっているGenerator / Discriminatorは、英語音声で学習されたContentVecをPhoneEmbedderに使用した状況でVCTKコーパスを使い学習されているはずです。hbj_nadareでは、そのGenerator / Discriminatorを、日本語データで学習されたHuBERT(rinna/japanese-hubert-base)をPhoneEmbedderにし、finetuningされている模様です。
hbj_nadareの結果が少し悪く見えてしまっている原因は、そもそも日本語音声の変換向けにモデルがチューニングされている可能性、および既にfinetuningされたものを今回さらにfinetuningしたわけなので少し過学習気味になり、ボコーダー感のあるノイズが乗ってしまった可能性が考えられます。Epoch数を減らし、日本語音声を取り扱うことで結果が変わる可能性がある点にはご注意下さい。
といっても、RVCの構造、事前学習済みモデルが公開されている、などにより自分の日本語音声だけを用意すれば、今回程度の声質変換は可能になるというのは非常に強力だなと思いました。
変換速度もリアルタイム(低遅延)で動作可能な様子なので、翻訳サービスや英語音声TTSサービスなどと組み合わせることで、自分の声でネイティブスピーカーとコミュニケーションを取ることも夢ではないかもしれません。
変換速度もリアルタイム(低遅延)で動作可能な様子なので、翻訳サービスや英語音声TTSサービスなどと組み合わせることで、自分の声でネイティブスピーカーとコミュニケーションを取ることも夢ではないかもしれません。
まとめ
今回は、「AIの力で英語ネイティブスピーカーになってみたいPart 2」ということで話題のRVCを活用してみました。RVCは、10分程度の音声データでもある程度の品質で音声変換可能なようなので、他にも色々と応用先を模索できればと思いました。またRVC以外にもDDSP-SVC[14]など、オープンソースな声質変換手法が公開されているので、今後も実験していきたいなと思います。
こういった形で、AaaS Tech Labでは、ビジネスの最適化などを目的としたデータサイエンス活用はもちろん、メディア・コンテンツ領域へのAI技術応用も進めております。
もしご興味を持っていただけた方がいらっしゃいましたら、worksをご覧いただいたり、contactからご連絡いただけたりしますと幸いです。
もしご興味を持っていただけた方がいらっしゃいましたら、worksをご覧いただいたり、contactからご連絡いただけたりしますと幸いです。
AaaS Tech Lab 小山田圭佑
<!—— SHARE ——>
//データサイエンティスト/AIエンジニア/ビジネスプラナー
小山田 圭佑
Keisuke Oyamada
==============
<‑‑
‑‑>



タグ一覧
#次世代メディアデータ基盤#メディアソリューション#TV視聴ログ#GPS位置情報データ#メディア・コンテンツ開発#レシピデータ#自然言語処理#音声処理#表情感情推定#脳波#画像生成#text2image#Diffusion Model#3Dモデリング#PIFu#Mixamo#音声合成#Zero-Shot learning#Multilingual TTS#最適化#イベント登壇#人工知能学会#Developers Summit#デブサミ#エモテク#TV番組分析#SNSデータ#声質変換#Voice Conversion#Retrieval-based Voice Changer#image to 3d#NeRF#Volume Rendering#3D Reconstruction#空中触覚デバイス#フォトグラメトリ#初音ミク#AIラッパー#雑誌データ分析