2023.01.26
AIの力で英語ネイティブスピーカーになってみたい
こんにちは。AaaS Tech Labの小山田です。
「2022年のAI」と言われると、画像生成技術を思い浮かべる人も多いのではないでしょうか?
一方でTTS(Text to Speech, テキスト音声合成)分野でも、「おしゃべりひろゆきメーカー」[1]や、TikTok上での「ヒカキンボイス」[2]など話題になった技術が多かった印象です。
一方でTTS(Text to Speech, テキスト音声合成)分野でも、「おしゃべりひろゆきメーカー」[1]や、TikTok上での「ヒカキンボイス」[2]など話題になった技術が多かった印象です。
ということで今回はTTSの活用に挑戦してみようと思います。
すごく簡単にTTSを図示すると下記のようなイメージです。つまり、発話させたいテキスト(および生成したい音声の話者情報)をAIにインプットすることで、それに対応する音声データを生成する技術です。
すごく簡単にTTSを図示すると下記のようなイメージです。つまり、発話させたいテキスト(および生成したい音声の話者情報)をAIにインプットすることで、それに対応する音声データを生成する技術です。

そこで今回は少しタスクの難易度を上げ、言語の壁を越えるようなTTSに挑戦します。
どういうことかと言うと、「英語が苦手な小山田でも、AIの力を使えば、ネイティブスピーカーのように発話できるようになるのでは?」というテーマに挑戦するということです。
どういうことかと言うと、「英語が苦手な小山田でも、AIの力を使えば、ネイティブスピーカーのように発話できるようになるのでは?」というテーマに挑戦するということです。
技術概要
最初に、「AIの力を使ってネイティブスピーカーになる」ために必要な技術要素を考えてみます。
大きくは、「用意すべきデータ」と「使用すべきAIモデル」という2要素が重要になるかと思います。
大きくは、「用意すべきデータ」と「使用すべきAIモデル」という2要素が重要になるかと思います。
まず、「用意すべきデータ」の観点で、下表の3パターンを考えました。
(「ターゲット話者」というのは、生成したい声の持ち主、つまり今回は小山田だと思ってください。)
(「ターゲット話者」というのは、生成したい声の持ち主、つまり今回は小山田だと思ってください。)

ここでは、Best / Better / Meaninglessという順位づけをしています。
「Meaningless」では、学習データとして、小山田が流暢に英語を話した音声データを学習に使用するイメージです。しかし今回はそもそも英語が話せない前提なので、この方法は実現不可能です…。
「Meaningless」では、学習データとして、小山田が流暢に英語を話した音声データを学習に使用するイメージです。しかし今回はそもそも英語が話せない前提なので、この方法は実現不可能です…。
次に「Better」では、英語ネイティブスピーカーの音声と、「小山田が日本語を発話したデータ」を混ぜて使用するイメージです。さすがに私も日本語なら人並みに発話できるので、データの準備としては実現可能です。
最後に「Best」では、学習には英語ネイティブスピーカーの音声のみを使用し、音声合成時にのみ小山田の日本語発話音声を使うイメージです。Betterとの違いは学習時にネイティブスピーカーのデータのみを使用する為、小山田以外の英語発話が苦手な方への転用も比較的容易という点です。
今回は精度比較の意味も込めて、Best / Betterの2つを実験してみました。
※Best / Better / Meaninglessは、あくまで私の現段階での所感に過ぎない点にはご注意ください。
今回は精度比較の意味も込めて、Best / Betterの2つを実験してみました。
※Best / Better / Meaninglessは、あくまで私の現段階での所感に過ぎない点にはご注意ください。
では続いて、Best / Betterを実現するためにどんな技術が必要か考えます。
まず、Bestの条件を満たすには、TTS技術の中でも、「Zero-Shot TTS」という技術が必要です。これは、学習データ中に存在しない話者の音声も生成できるようなTTS技術です。
もちろん、まったく知らない人間の音声を生成することは不可能なので、生成時にリファレンスとして、生成したい人の音声を適当な長さで与えます。
今回はZero-Shot TTS系の技術として、「YourTTS」[5]というモデルを使用します。
簡単なイメージとして、YourTTSによるZero-Shotな音声合成を図示すると下記のようになります。上述した一般的なTTSでは話者IDをインプットしましたが、YourTTSではターゲット話者の音声をAIでベクトル化し、TTSモデルにインプットします。
もちろん、まったく知らない人間の音声を生成することは不可能なので、生成時にリファレンスとして、生成したい人の音声を適当な長さで与えます。
今回はZero-Shot TTS系の技術として、「YourTTS」[5]というモデルを使用します。
簡単なイメージとして、YourTTSによるZero-Shotな音声合成を図示すると下記のようになります。上述した一般的なTTSでは話者IDをインプットしましたが、YourTTSではターゲット話者の音声をAIでベクトル化し、TTSモデルにインプットします。

(詳細かつ正確なYourTTSの処理イメージは、論文等をご確認ください。)
次にBetterについては、TTSの中でも、Multilingual TTS(多言語テキスト音声合成)という技術が必要です。一般的なTTSでは1つの言語のみを学習しますが、Multilingual TTSでは2つ以上の言語について同時に学習するイメージになります。今回は「VITS」[6]というTTS技術を少し拡張してMultilingual TTSに挑戦します。
「YourTTS」や「VITS」についての詳細は、文量の都合で割愛します。
ただ、理解が進むのではないかと思う記事を添付しますので、論文と一緒にご確認いただくと良いかもしれません。
ちなみにYourTTSはVITSを拡張したようなイメージなので、まずはVITSについて理解するとYourTTSに関しての理解が早い可能性があります。
YourTTS : https://coqui.ai/blog/tts/yourtts-zero-shot-text-synthesis-low-resource-languages
VITS : https://qiita.com/zassou65535/items/00d7d5562711b89689a8
ただ、理解が進むのではないかと思う記事を添付しますので、論文と一緒にご確認いただくと良いかもしれません。
ちなみにYourTTSはVITSを拡張したようなイメージなので、まずはVITSについて理解するとYourTTSに関しての理解が早い可能性があります。
YourTTS : https://coqui.ai/blog/tts/yourtts-zero-shot-text-synthesis-low-resource-languages
VITS : https://qiita.com/zassou65535/items/00d7d5562711b89689a8
YourTTSを使ったBestに関する実験
では、YourTTS によるBestの実験を考えます。
実装については、GitHub上にコードと学習済みモデルが公開されているので、今回はそちらを使用しました。
詳細は下記リンクをご確認ください。Colab上でのデモも公開されています。
YourTTS : https://github.com/Edresson/YourTTS
Coqui TTS : https://github.com/coqui-ai/tts
実装については、GitHub上にコードと学習済みモデルが公開されているので、今回はそちらを使用しました。
詳細は下記リンクをご確認ください。Colab上でのデモも公開されています。
YourTTS : https://github.com/Edresson/YourTTS
Coqui TTS : https://github.com/coqui-ai/tts
まず、生成結果だけを聞かされてもピンとこないかと思うので、小山田の音声データサンプルを載せておきます。
念の為補足すると、思いつきで話したのではなく、「ITAコーパス」[7]という音声合成向けのパブリックドメインな文章コーパスをいくつか読み上げています。
念の為補足すると、思いつきで話したのではなく、「ITAコーパス」[7]という音声合成向けのパブリックドメインな文章コーパスをいくつか読み上げています。
続いて、YourTTSで小山田が話したような英語音声を生成した結果です。
こちらは、リファレンスとして与える音声データの長さを、2秒 / 17秒 / 29秒 / 118秒と変化させて実験しました。
また、与えたテキストは下記です。
(そもそも英語文章として、文法等が変といった話があるかもしれませんが、そこは目を瞑っていただけると幸いです。)
こちらは、リファレンスとして与える音声データの長さを、2秒 / 17秒 / 29秒 / 118秒と変化させて実験しました。
また、与えたテキストは下記です。
(そもそも英語文章として、文法等が変といった話があるかもしれませんが、そこは目を瞑っていただけると幸いです。)
I have experimented with AI to see if it can help me speak English as fluently as native speakers.
(AIを使って、ネイティブスピーカーのように流暢に英語を話せるようになるかどうか、実験してみました。)
(AIを使って、ネイティブスピーカーのように流暢に英語を話せるようになるかどうか、実験してみました。)
生成結果は下記です。
少なくともネイティブスピーカーのような発音やテンポで話した英語音声は生成できていそうです。
また、似ているかどうかという観点で考えると、リファレンス音声を2秒や17秒とした場合よりは、30秒程度以上与えた方が、似ているような気がしました。
音声の品質(ノイズが小さいなど)といった観点でも、30秒程度は与えた方が良いかもしれません。
また、似ているかどうかという観点で考えると、リファレンス音声を2秒や17秒とした場合よりは、30秒程度以上与えた方が、似ているような気がしました。
音声の品質(ノイズが小さいなど)といった観点でも、30秒程度は与えた方が良いかもしれません。
もう少し小山田っぽくなっているかを分かりやすくするために、「JVSコーパス」[8]のid=001の男性音声を与えたパターンでも実験してみました。
1つ目の動画が実データの音声サンプル、2つ目の動画が生成結果です。
1つ目の動画が実データの音声サンプル、2つ目の動画が生成結果です。
こちらと小山田音声の生成結果を比較すると、リファレンスとして与える音声によって、生成される音声に明確な変化があることが分かるかと思います。
といっても個人的には、Zero-Shotという条件で、完璧に本人らしい音声を生成するというのは、まだ簡単ではないという印象を今回の実験結果からはうけました。
※日本語音声を学習していないモデルに対して、日本語音声をリファレンスとして与えて音声合成を行なうという(おそらく)難しいタスクを解かせているため、英語音声のみで実験するなどで状況が変わる可能性は十分にあります。
といっても個人的には、Zero-Shotという条件で、完璧に本人らしい音声を生成するというのは、まだ簡単ではないという印象を今回の実験結果からはうけました。
※日本語音声を学習していないモデルに対して、日本語音声をリファレンスとして与えて音声合成を行なうという(おそらく)難しいタスクを解かせているため、英語音声のみで実験するなどで状況が変わる可能性は十分にあります。
VITSを使ったBetterに関する実験
続いてBetterに関する実験を考えます。
一般的なTTSに関するVITSの実装は、色々な方が公開しています。
オフィシャルの実装 : https://github.com/jaywalnut310/vits
ESPNetでの実装 : https://github.com/espnet/espnet/tree/master/egs2/jsut/tts1
Coqui TTSでの実装 : https://github.com/coqui-ai/TTS/tree/dev/recipes
一般的なTTSに関するVITSの実装は、色々な方が公開しています。
オフィシャルの実装 : https://github.com/jaywalnut310/vits
ESPNetでの実装 : https://github.com/espnet/espnet/tree/master/egs2/jsut/tts1
Coqui TTSでの実装 : https://github.com/coqui-ai/TTS/tree/dev/recipes
特にESPNetではJUST[9]やJVSコーパスといった日本語データセットに関するレシピ(実験条件などが記載された設定ファイル)や学習済みモデルが公開されています。
また、Coqui TTSではVITSを使い、Multilingual TTSを実装する為のレシピが公開されています。
今回はCoqui TTSのレシピを参考に実験しました。
また、Coqui TTSではVITSを使い、Multilingual TTSを実装する為のレシピが公開されています。
今回はCoqui TTSのレシピを参考に実験しました。
次に学習に使う音声データについて考えます。
当たり前ですが、小山田の音声データを学習した(Multilingual) TTSはどこにも公開されていないので、1から学習させる必要があります。
今回は、英語音声データとして「VCTKコーパス」[10]を使いました。
また、小山田の音声データは、ITAコーパスのうち「EMOTION100」という100文章を読み上げる形で用意しました。(音声サンプルは前述の通りです。)
当たり前ですが、小山田の音声データを学習した(Multilingual) TTSはどこにも公開されていないので、1から学習させる必要があります。
今回は、英語音声データとして「VCTKコーパス」[10]を使いました。
また、小山田の音声データは、ITAコーパスのうち「EMOTION100」という100文章を読み上げる形で用意しました。(音声サンプルは前述の通りです。)
ここまでで学習に必要な音声データは揃いましたが、TTSの学習には音声に対応するテキストデータも用意する必要があります。
少なくとも日本語データに関するTTSでは一般的に、発話内容に関する文章を音素といった形式に変換し使用します。
例えば、「こんにちは」を音素表記すると、「k o N n i ch i w a」となります。
音素表記といっても様々な手法が存在しますし、韻律記号といわれるアクセントなどに関する情報を加味するケースもあるので、上記の表記は簡単な例だと考えてください。
また、私はあまり英語に関するTTSに詳しくないのですが、英語にも音素という考え方は存在するようです。(VCTKコーパスで音素アライメントをとるコードの例 : https://github.com/r9y9/deepvoice3_pytorch)
少なくとも日本語データに関するTTSでは一般的に、発話内容に関する文章を音素といった形式に変換し使用します。
例えば、「こんにちは」を音素表記すると、「k o N n i ch i w a」となります。
音素表記といっても様々な手法が存在しますし、韻律記号といわれるアクセントなどに関する情報を加味するケースもあるので、上記の表記は簡単な例だと考えてください。
また、私はあまり英語に関するTTSに詳しくないのですが、英語にも音素という考え方は存在するようです。(VCTKコーパスで音素アライメントをとるコードの例 : https://github.com/r9y9/deepvoice3_pytorch)
しかしここで問題になるのは、英語と日本語では共通の音素表記方法が、おそらく存在しないという点です。(少なくとも私は知りません。)
なので、英語にしか存在しない音素やその逆も存在しますし、同じ表記でも発音の仕方が異なるケースも存在するはずです。
もちろん、この問題は日本語 / 英語 間に限った話ではなく、他の言語間でも存在する問題です。
この問題に対して、一般的にMultilingual TTSではどう対処するか分かりませんが、少なくともCoqui TTSのレシピ[11]上では、音素などに変換せずに、文字単位で分割して、モデルにインプットしているようです。
今回はこの方式にならい、テキストデータを構築しました。
この処理を簡単にまとめると、下図のようなイメージとなります。
なので、英語にしか存在しない音素やその逆も存在しますし、同じ表記でも発音の仕方が異なるケースも存在するはずです。
もちろん、この問題は日本語 / 英語 間に限った話ではなく、他の言語間でも存在する問題です。
この問題に対して、一般的にMultilingual TTSではどう対処するか分かりませんが、少なくともCoqui TTSのレシピ[11]上では、音素などに変換せずに、文字単位で分割して、モデルにインプットしているようです。
今回はこの方式にならい、テキストデータを構築しました。
この処理を簡単にまとめると、下図のようなイメージとなります。
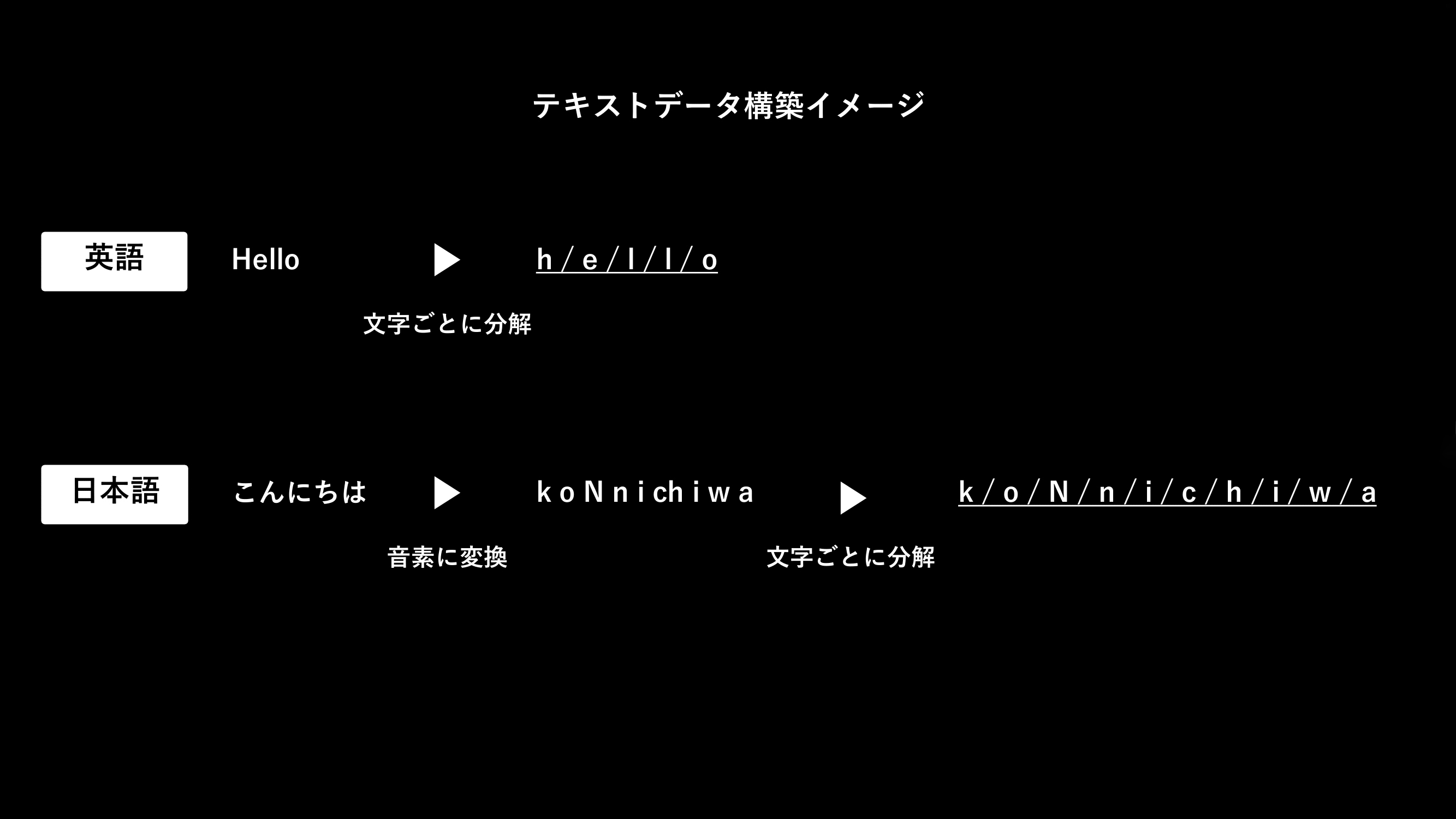
下線の引かれたテキストが最終的に使用されるものです。
特に日本語について、本来なら「ch」で1音素であるところを「c」と「h」に分割するなどの気持ち悪さはありますが、一旦こちらで進めました。
特に日本語について、本来なら「ch」で1音素であるところを「c」と「h」に分割するなどの気持ち悪さはありますが、一旦こちらで進めました。
ということで、気になる点はありつつ、上記のような設定で、音声とテキストデータを準備し、VITSによるMultilingual TTSに関して実験しました。
ここまでに記述した内容以外の実験設定は、基本的にCoqui TTSレシピ通りですので、気になる方はこちら[12]をご確認ください。
では長くなりましたが、下記がVITSによるMultilingual TTSにて生成した小山田の英語発話音声です。
インプットしたテキストは、YourTTSと同様です。
インプットしたテキストは、YourTTSと同様です。
いかがでしょうか?
個人的には、YourTTSよりも自分の声に近づいた気がします。ただ、話速がYourTTSよりもゆっくりであるなど、ネイティブスピーカーらしさという観点で考えると、判断が難しいなとは思いました。(もちろん、私が英語を発話するよりは明らかに流暢だと思います…笑)
また、「AI」や「fluently」などの発音が潰れている気もします。このあたりは音素表記を見直す、データ数を増やす、サンプリング周波数を上げて音の解像度を高めるなど、改良の余地が大きく残る点かと思います。
とはいえ、Multilingual TTSという一般的なTTSよりもオープンな情報が少なく、手探りの中で試してみた結果としては、思ったよりもうまくいった感触です。
個人的には、YourTTSよりも自分の声に近づいた気がします。ただ、話速がYourTTSよりもゆっくりであるなど、ネイティブスピーカーらしさという観点で考えると、判断が難しいなとは思いました。(もちろん、私が英語を発話するよりは明らかに流暢だと思います…笑)
また、「AI」や「fluently」などの発音が潰れている気もします。このあたりは音素表記を見直す、データ数を増やす、サンプリング周波数を上げて音の解像度を高めるなど、改良の余地が大きく残る点かと思います。
とはいえ、Multilingual TTSという一般的なTTSよりもオープンな情報が少なく、手探りの中で試してみた結果としては、思ったよりもうまくいった感触です。
[付録]英語ネイティブスピーカーは日本語を話せるようになるのか?
上述した内容までで終わりにしても良いのですが、せっかくMultilingual TTSモデルを作ったので、英語ネイティブスピーカーの声で日本語音声を生成してみます。
ターゲット話者は、VCTKコーパスのID「p230」と「p256」を使用しました。
インプットしたテキストは下記です。
ターゲット話者は、VCTKコーパスのID「p230」と「p256」を使用しました。
インプットしたテキストは下記です。
こんにちは。今日は多言語テキスト音声合成に挑戦してみました。
訛り?という表現が正しいか分かりませんが、英語のような発話リズムをもった日本語音声が生成された気がします。あまりこういったTTS結果を聞いたことがなかったので、個人的には興味深い結果になったと思っています。
もっというと、自分の声らしい英語音声の生成よりも、こちらの生成結果が得られた時の方が、ちょっとテンションが上がりました笑
もっというと、自分の声らしい英語音声の生成よりも、こちらの生成結果が得られた時の方が、ちょっとテンションが上がりました笑
最後に
今回は「英語が苦手な小山田でも、AIの力を使えば、ネイティブスピーカーのように発話できるようになるのか?」というテーマで、TTS技術の応用に挑戦してみました。
これまでの経験として、単純に日本語データのみを用いたTTSを実装したことはありましたが、日本語話者に英語を話させるというタスクは取り扱ったことがなかったので、大変だった反面、良い勉強になりました。
本格的に実応用するには、音質など改善すべき点はありますが、思ったよりも自分に近い声になったような気はしています。
また付録として、英語ネイティブスピーカーの声で日本語音声を生成してみましたが、絶妙なぎこちなさ?を持つ音声が生成され、興味深いなと思いました。
個人的には、高品質/高精度なTTSという方向性だけでなく、何らかの意味でユニークさをもった音声合成に挑戦するという方向性も面白いかもしれないと思わされる結果だと感じています。
これまでの経験として、単純に日本語データのみを用いたTTSを実装したことはありましたが、日本語話者に英語を話させるというタスクは取り扱ったことがなかったので、大変だった反面、良い勉強になりました。
本格的に実応用するには、音質など改善すべき点はありますが、思ったよりも自分に近い声になったような気はしています。
また付録として、英語ネイティブスピーカーの声で日本語音声を生成してみましたが、絶妙なぎこちなさ?を持つ音声が生成され、興味深いなと思いました。
個人的には、高品質/高精度なTTSという方向性だけでなく、何らかの意味でユニークさをもった音声合成に挑戦するという方向性も面白いかもしれないと思わされる結果だと感じています。
こういった形で、AaaS Tech Labでは、ビジネスの最適化などを目的としたデータサイエンス活用はもちろん、メディア・コンテンツ領域へのAI技術応用も進めております。
もしご興味を持っていただけた方がいらっしゃいましたら、worksをご覧いただいたり、contactからご連絡いただけたりしますと幸いです。
もしご興味を持っていただけた方がいらっしゃいましたら、worksをご覧いただいたり、contactからご連絡いただけたりしますと幸いです。
AaaS Tech Lab 小山田圭佑
<!—— SHARE ——>
//データサイエンティスト/AIエンジニア/ビジネスプラナー
小山田 圭佑
Keisuke Oyamada
==============
<‑‑
‑‑>



タグ一覧
#次世代メディアデータ基盤#メディアソリューション#TV視聴ログ#GPS位置情報データ#メディア・コンテンツ開発#レシピデータ#自然言語処理#音声処理#表情感情推定#脳波#画像生成#text2image#Diffusion Model#3Dモデリング#PIFu#Mixamo#音声合成#Zero-Shot learning#Multilingual TTS#最適化#イベント登壇#人工知能学会#Developers Summit#デブサミ#エモテク#TV番組分析#SNSデータ#声質変換#Voice Conversion#Retrieval-based Voice Changer#image to 3d#NeRF#Volume Rendering#3D Reconstruction#空中触覚デバイス#フォトグラメトリ#初音ミク#AIラッパー#雑誌データ分析