2024.02.16
フォトグラメトリ映像制作の背景 |「体験!さわれる!?不思議な未来の天気」において
先日ご紹介しましたが「COOL CHOICE 2023 in SHIZUOKA」にて、「体験!さわれる!?不思議な未来の天気」という展示を行いました。
この中でフォトグラメトリを活用した映像制作を行ったのですが、本記事ではその制作過程を一部ご紹介します。
イベントおよび展示の概要についてはこちら[1]をご覧ください。
この中でフォトグラメトリを活用した映像制作を行ったのですが、本記事ではその制作過程を一部ご紹介します。
イベントおよび展示の概要についてはこちら[1]をご覧ください。
※本記事では、主にフォトグラメトリ処理について考えます。フォトグラメトリにより生成した3DモデルをUE5[2]に取り込み映像を制作する部分、静岡県が公開する県内の点群データ(VIRTUAL SHIZUOKA[3])を活用するとどうなりうるのかなどは、ここでは取り扱わないこととします。
フォトグラメトリとは?
フォトグラメトリは、様々な位置 / 角度で撮影された複数枚の写真から3Dモデルを生成する手法です。

Blender[4]などを活用し現実の物体をモデリングするよりも、効率的かつ場合によっては精巧に3Dモデル化できる点がフォトグラメトリの利点かと思います。
そのため現実の街並みをVR空間上で体験[5]できるようにしたり、歴史的な建造物のデジタルアーカイブを制作[6]したりする場合、フォトグラメトリが活用されるケースも多くあります。
そのため現実の街並みをVR空間上で体験[5]できるようにしたり、歴史的な建造物のデジタルアーカイブを制作[6]したりする場合、フォトグラメトリが活用されるケースも多くあります。
フォトグラメトリ / LiDAR / NeRFの違い
現実の物体を3Dモデル化する手法というと、フォトグラメトリ以外にもLiDAR[7]やNeRF[8]といった手法も存在します。
LiDARはレーザー光を照射し、その反射光の情報を解析することで物体検知や3Dモデル化を行う手法です。最近ではiPhone 12 Pro以降のiPhoneでLiDAR機能が搭載されたため、簡易にスマホで試すことも可能です。
NeRFは画像をNeural Networkで処理し、ある視点からの見え方を推定するような手法であり、3Dモデルを生成することも可能です。NeRFに関してはこちらの記事[9]で解説しているので合わせてご覧ください。
LiDARはレーザー光を照射し、その反射光の情報を解析することで物体検知や3Dモデル化を行う手法です。最近ではiPhone 12 Pro以降のiPhoneでLiDAR機能が搭載されたため、簡易にスマホで試すことも可能です。
NeRFは画像をNeural Networkで処理し、ある視点からの見え方を推定するような手法であり、3Dモデルを生成することも可能です。NeRFに関してはこちらの記事[9]で解説しているので合わせてご覧ください。
今回の制作ではiPhoneを撮影機器とし、上記3手法を試しました。
LiDARはiPhoneの専用アプリ、NeRFはLuma AI[10]のアプリ、フォトグラメトリはiPhoneで撮影した画像をReality Capture[11]に取り込むことで実施しました。
あくまで上記条件での検証を通じて感じたことですが、
LiDARはiPhoneの専用アプリ、NeRFはLuma AI[10]のアプリ、フォトグラメトリはiPhoneで撮影した画像をReality Capture[11]に取り込むことで実施しました。
あくまで上記条件での検証を通じて感じたことですが、
| 撮影効率 | 処理速度 | モデル化可能範囲 | テクスチャ解像度 | |
|---|---|---|---|---|
| フォトグラメトリ | △ | △ | ◎ | ◎ |
| LiDAR | ◎ | ◎ | △ | ◎ |
| NeRF | 〇 | 〇 | ◎ | △ |
という違いがあった印象でした。
まず撮影やモデル化処理の負荷でいうと、LiDARが効率的でした。専用アプリを使用すると、まだスキャンされていない領域がリアルタイムに確認できた点が特に撮影効率を高めてくれたと思います。
また3Dモデル化の処理もLiDARが最も短く、手元のスマートフォンで処理が完結する点も楽で良いなと思いました。
一方でLiDARはレーザー光が届かない領域はモデル化が不可能です。特に今回はiPhoneを使用したため、建物の2階程度の高さがスキャンできる限界でした。例えば下記はLiDARで簡易的に街並みをスキャンした点群データですが、壁や道路は十分にスキャンできているのに対し、建物の上部は途切れてしまっています。
また3Dモデル化の処理もLiDARが最も短く、手元のスマートフォンで処理が完結する点も楽で良いなと思いました。
一方でLiDARはレーザー光が届かない領域はモデル化が不可能です。特に今回はiPhoneを使用したため、建物の2階程度の高さがスキャンできる限界でした。例えば下記はLiDARで簡易的に街並みをスキャンした点群データですが、壁や道路は十分にスキャンできているのに対し、建物の上部は途切れてしまっています。

よって、ビルなどをスキャンする場合は、NeRFやフォトグラメトリの方が適している気がしています。今回の制作では、低い建物しかスキャンできないと映像の迫力に欠けると判断し、LiDARは使用しませんでした。
※あくまでiPhoneのLiDAR機能を利用した場合の話であり、LiDAR専用の機器を活用すると高い建物もスキャン可能になる可能性はあります。
※あくまでiPhoneのLiDAR機能を利用した場合の話であり、LiDAR専用の機器を活用すると高い建物もスキャン可能になる可能性はあります。
次にNeRFについて考えると、フォトグラメトリよりざっくりとした撮影でも、それなりのモデル化が可能な印象でした。またLuma AIを使うことで、クラウドサーバー上で処理できるため、現地でうまくモデル化できたか確認することもできます。一方でテクスチャ解像度という観点ではフォトグラメトリのほうが優れていると考えています。
下記の記事でも言われていますが、NeRFはフォトグラメトリよりもテクスチャ解像度が低いように思います。
https://jouer.co.jp/360-vs-photogrammetry-vs-nerf/
https://vigne-cla.com/19-17/
下記の記事でも言われていますが、NeRFはフォトグラメトリよりもテクスチャ解像度が低いように思います。
https://jouer.co.jp/360-vs-photogrammetry-vs-nerf/
https://vigne-cla.com/19-17/
ということで振り返るとフォトグラメトリは撮影からモデル化に至るまでの作業が最も大変な印象でしたが、最終的に得られる3Dモデルの品質が高いと判断し、採用しました。
フォトグラメトリによる3Dモデル化
ここからはフォトグラメトリによる3Dモデル化の流れや、注意点について考えます。
フォトグラメトリは大まかに
1. 各写真が撮影されたカメラ位置の推定
2. 3Dモデルのメッシュ生成
3. テクスチャの生成
4. FBXなどの形式で出力する
というステップからなります。
フォトグラメトリは大まかに
1. 各写真が撮影されたカメラ位置の推定
2. 3Dモデルのメッシュ生成
3. テクスチャの生成
4. FBXなどの形式で出力する
というステップからなります。
前述の通り今回はReality Captureを使用しフォトグラメトリを行いましたが、上記ステップを全てReality Capture上で完結させることが可能です。
1. カメラ位置の推定について
上記のステップの中で最も重要な部分は、カメラ位置推定かと思います。
ここでいうカメラ位置とは、ある写真が「どの位置」から「どんな角度」で撮影されたのかという情報です。そんな情報を、入力された1枚1枚の写真に対して推定することがカメラ位置推定です。
実際にカメラ位置推定を行うと、Reality Capture上では下記のように表示されます。真ん中あたりに描画されている複数の四角形が推定結果です。
ここでいうカメラ位置とは、ある写真が「どの位置」から「どんな角度」で撮影されたのかという情報です。そんな情報を、入力された1枚1枚の写真に対して推定することがカメラ位置推定です。
実際にカメラ位置推定を行うと、Reality Capture上では下記のように表示されます。真ん中あたりに描画されている複数の四角形が推定結果です。
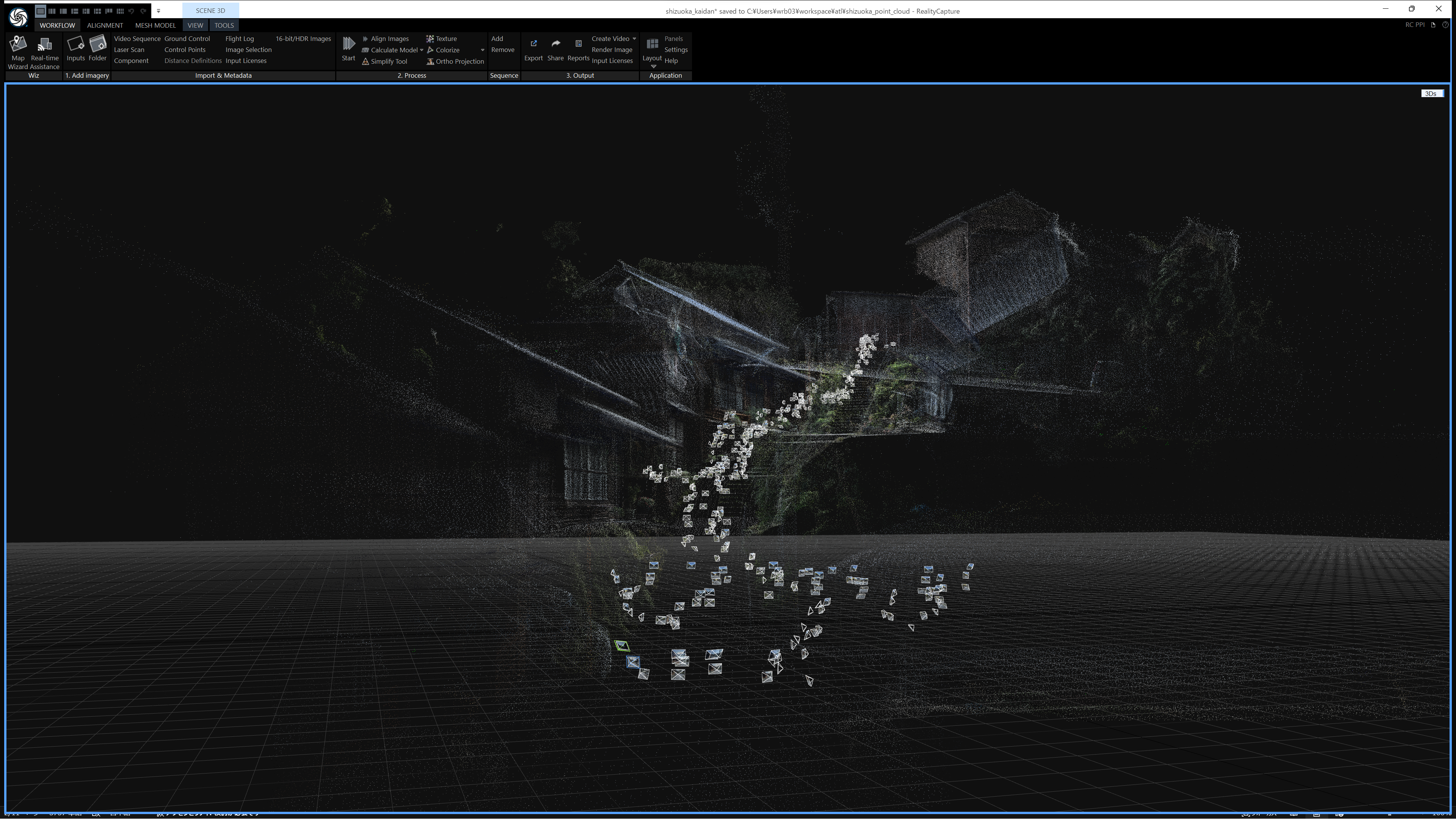
うまくカメラ位置推定ができると、撮影した写真の枚数とほぼ同数のカメラ位置を示す四角形が描画されます。
逆に推定がうまくいかないと、1つの3Dモデルとして制作したい物体が、細かい複数の物体に分割されてしまったりします。またそれにより、後段で生成されるメッシュが現実とはかけ離れ、求める品質での3Dモデル化ができなくなります。
逆に推定がうまくいかないと、1つの3Dモデルとして制作したい物体が、細かい複数の物体に分割されてしまったりします。またそれにより、後段で生成されるメッシュが現実とはかけ離れ、求める品質での3Dモデル化ができなくなります。
では、カメラ位置推定の精度を高めるには、どうすれば良いでしょうか?
今回取り組んだ経験の中では、下記3点が大事なのかなと思いました。
A. 各写真同士で撮影対象に十分重複を持たせる
B. 特徴点を含む写真を撮影する
C. Reality Captureのcontrol point機能を使う
A, Bのポイントは、そもそもの撮影段階で注意すべき点です。Cは撮影後にうまくいかなかった場合に、補正をかけるイメージになります。
今回取り組んだ経験の中では、下記3点が大事なのかなと思いました。
A. 各写真同士で撮影対象に十分重複を持たせる
B. 特徴点を含む写真を撮影する
C. Reality Captureのcontrol point機能を使う
A, Bのポイントは、そもそもの撮影段階で注意すべき点です。Cは撮影後にうまくいかなかった場合に、補正をかけるイメージになります。
ここからは下記のような空間を例にA~Cのポイントについて考えます。
(※画像は既にフォトグラメトリで3Dモデル化されたものですが、ここでは現実空間だと思ってください。)
(※画像は既にフォトグラメトリで3Dモデル化されたものですが、ここでは現実空間だと思ってください。)

A : 各写真同士で撮影対象に十分重複を持たせる
例えば、下記の赤と青のコーンで示した位置/角度から写真を撮影します。(コーンの尖っている方向が、カメラの向いている方向です。)

すると、赤のコーン位置からは下記1枚目の写真、青のコーンからは2枚目の写真が撮影されました。


では上記の2枚の写真から、撮影されたカメラ位置がどのあたりか推定することはできるでしょうか?また、2か所のカメラ位置がどの程度離れているか、それぞれがどんな位置を向いていたか判断することはできるでしょうか?
一般的なカメラ位置推定手法では不可能ですし、人間でも2枚の写真だけから上記で示したコーンの位置を推定することは不可能でしょう。
これは非常に極端な例ですが、各写真同士で重複をもたせなければならない理由は想像できるかと思います。フォトグラメトリでは、あくまで写真に写っている要素からカメラ位置を推定するため、全く異なる領域を映した写真だけを入力しても、どこから撮影されたか判断できないということです。
ちなみに70, 80%程度映す領域に重複を持たせながら撮影すると、カメラ位置推定がうまくいきやすいようです。
一般的なカメラ位置推定手法では不可能ですし、人間でも2枚の写真だけから上記で示したコーンの位置を推定することは不可能でしょう。
これは非常に極端な例ですが、各写真同士で重複をもたせなければならない理由は想像できるかと思います。フォトグラメトリでは、あくまで写真に写っている要素からカメラ位置を推定するため、全く異なる領域を映した写真だけを入力しても、どこから撮影されたか判断できないということです。
ちなみに70, 80%程度映す領域に重複を持たせながら撮影すると、カメラ位置推定がうまくいきやすいようです。
B : 特徴点を含む写真を撮影する
「特徴点」とは画像処理技術における専門用語ですが、ここでは目印のようなものだと思ってください。
今回は下記のような位置から撮影を行ってみます。
今回は下記のような位置から撮影を行ってみます。

すると、下記のような2枚の写真が撮影されました。下記1枚目が赤のコーン、2枚目が青のコーンから撮影された写真です。


互いのカメラ位置が近い状況で撮影されているので、撮影された領域の重複は十分なはずです。しかし、この2枚の写真からカメラ位置推定を行うことは難しいと考えられます。なぜかというと、グレーの石畳しか写っておらず、何か目印として使えそうな情報(特徴点)が存在しません。かなり極端な例ですが、実際にこういった写真はカメラ位置推定がうまくいかないことが多いです。
一方で地面も撮影しないと、最終的な3Dモデルとして地面が存在しないモノができあがってしまいます。
そこでカメラアングルを上げて、地面も写しつつ地面以外も写るように撮影します。
下記二枚は上記写真のアングルだけを変えたものです。
一方で地面も撮影しないと、最終的な3Dモデルとして地面が存在しないモノができあがってしまいます。
そこでカメラアングルを上げて、地面も写しつつ地面以外も写るように撮影します。
下記二枚は上記写真のアングルだけを変えたものです。


このように撮影すると、左にある看板やトンネル内の電灯など、特徴点として機能するような目印が写り込み、カメラ位置が推定できるようになります。
ただし撮影対象地に同じ看板が複数存在すると、特徴点として機能しにくくなります。実際、商店街の撮影では同じ看板が2つあったのですが、それらはうまく特徴点として機能しませんでした。
ただし撮影対象地に同じ看板が複数存在すると、特徴点として機能しにくくなります。実際、商店街の撮影では同じ看板が2つあったのですが、それらはうまく特徴点として機能しませんでした。
特徴点については、上述のNeRF関連記事[12]でもう少し詳しく触れています。
※ポイントA, Bを説明するうえで、状況をシンプルにするために2枚の写真を考えましたが、実際には数十~数百枚の撮影が必要です。ポイントA, Bをおさえても、2枚の写真”だけ”で3Dモデル化できる可能性は低い点にはご注意ください。
C : Reality Captureのcontrol points機能を使う
control points機能とは、カメラ位置推定がうまくいかなかった場合に、人手で何枚かの画像にcontrol pointという目印のようなものを設定する機能です。
例えば、下記2枚の写真について考えます。


人間の目で見れば同じのような場所を撮影した写真であることは明らかだと思いますが、仮にカメラ位置推定に失敗したとしましょう。このような状況で活用できるのが、Reality Captureのcontrol points機能です。
まず、2枚の写真で共通していてかつ、特徴点として機能しそうな要素を探します。そして、そのような場所にcontrol pointを設置します。
まず、2枚の写真で共通していてかつ、特徴点として機能しそうな要素を探します。そして、そのような場所にcontrol pointを設置します。
例えば下記のようにトンネル上部の看板の角に点を設置するイメージです。
(下記はあくまでイメージであり、実際にはもっと小さな点で詳細な位置を指定します。)
(下記はあくまでイメージであり、実際にはもっと小さな点で詳細な位置を指定します。)


このように複数枚の写真に対して、同じオブジェクトが写った位置にcontrol pointを設置することで、どこが同じ場所かという事前情報を持った状態でカメラ位置推定が行われるため、失敗した写真に対してもカメラ位置推定がうまくいく場合があります。
といっても、撮影対象が大規模になり、写真の枚数が増えるほど、control pointの設置作業に時間がかかります。また、必ずしも推定精度を高められるわけでもありません。よって、理想としてはcontrol points機能を使わずとも位置推定がうまくいくような撮影を心掛けたほうが良いです。
といっても、撮影対象が大規模になり、写真の枚数が増えるほど、control pointの設置作業に時間がかかります。また、必ずしも推定精度を高められるわけでもありません。よって、理想としてはcontrol points機能を使わずとも位置推定がうまくいくような撮影を心掛けたほうが良いです。
今回の制作においては、特に静岡駅近くの人通りが多いエリアでcontrol points機能が役立ちました。
(当たり前ですが)通行の妨げにならないように撮影する必要があるため、人通りが多いエリアでは、撮影の中断も多く発生します。また自動車用の道路に立ち入ってまで撮影するわけにもいきません。そうなると、どうしてもA,Bで示したポイントに準拠した撮影が困難でした。(そもそも、フォトグラメトリ用の撮影が初めてであったことも大きな要因ですが…。)
このような状況でもなんとか3Dモデル化できたのはcontrol points機能があったからだと思います。
(当たり前ですが)通行の妨げにならないように撮影する必要があるため、人通りが多いエリアでは、撮影の中断も多く発生します。また自動車用の道路に立ち入ってまで撮影するわけにもいきません。そうなると、どうしてもA,Bで示したポイントに準拠した撮影が困難でした。(そもそも、フォトグラメトリ用の撮影が初めてであったことも大きな要因ですが…。)
このような状況でもなんとか3Dモデル化できたのはcontrol points機能があったからだと思います。
2. 3Dモデルのメッシュ生成
次に3Dモデルのメッシュ生成について考えます。
カメラ位置推定が十分にうまくいくと、ある程度綺麗なメッシュが生成できます。しかし、建物と空が合体してしまったり、空中に謎の物体が浮遊してしまうケースも多いです。
例えば、「宇津ノ谷峠」というエリアの3Dモデルは、フォトグラメトリ結果をそのまま表示すると下記のようになっていました。
カメラ位置推定が十分にうまくいくと、ある程度綺麗なメッシュが生成できます。しかし、建物と空が合体してしまったり、空中に謎の物体が浮遊してしまうケースも多いです。
例えば、「宇津ノ谷峠」というエリアの3Dモデルは、フォトグラメトリ結果をそのまま表示すると下記のようになっていました。
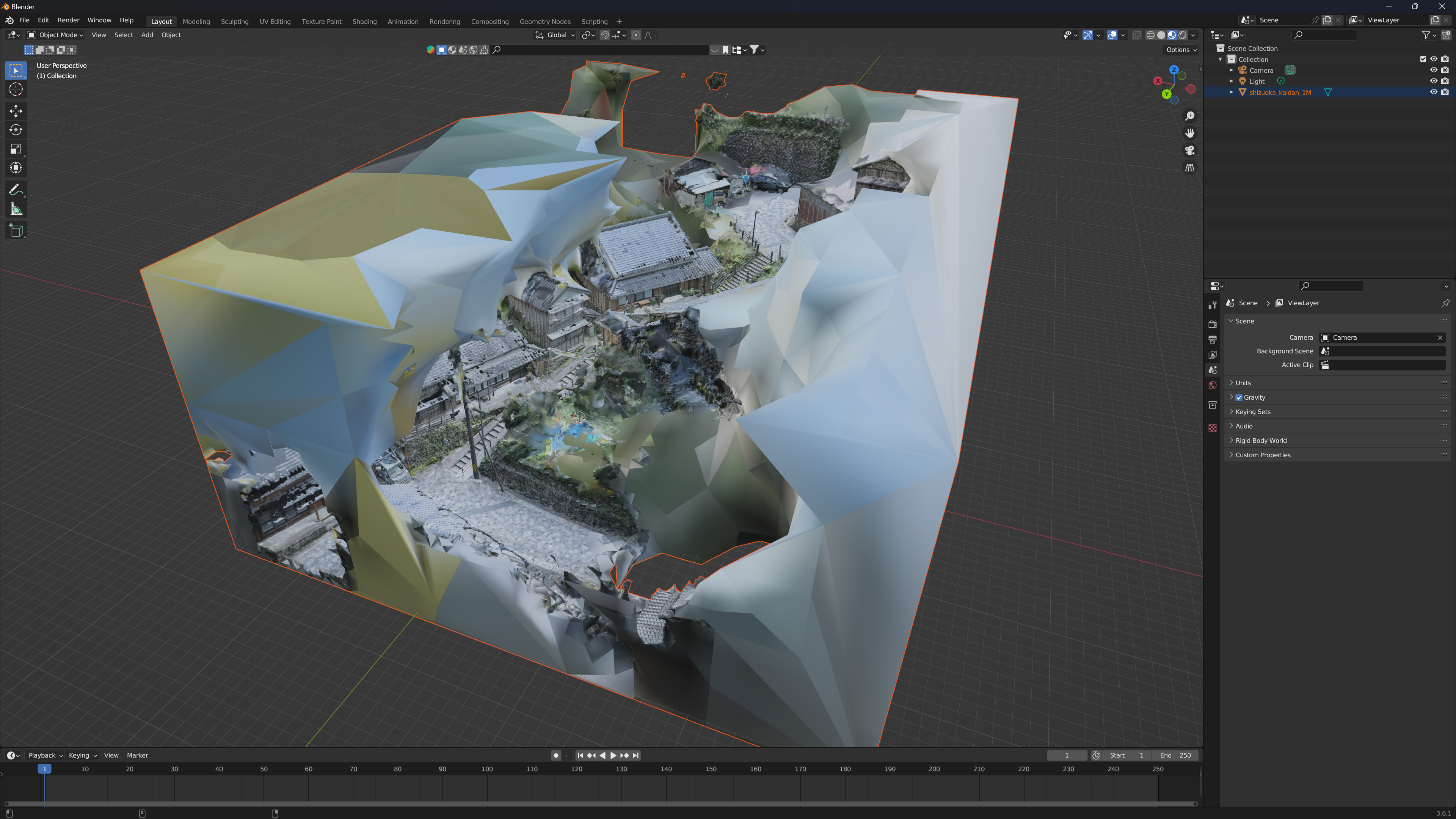
真ん中あたりに建物がモデル化されていますが、その周囲は壁のようなモノで覆われています。これをUE5などに取り込むと、太陽光などが周囲の壁で遮られ、不自然な影が発生してしまいます。また高い位置から俯瞰で映像を撮影する際に、謎の壁が写り込み不自然なものになります。
そこでBlenderなどのCGモデリングツールで、不必要なメッシュを削除していきます。今回はシンプルに周りを覆っていた壁を削除する作業を行いました。
ある程度修正した3Dモデルは下記です。
そこでBlenderなどのCGモデリングツールで、不必要なメッシュを削除していきます。今回はシンプルに周りを覆っていた壁を削除する作業を行いました。
ある程度修正した3Dモデルは下記です。
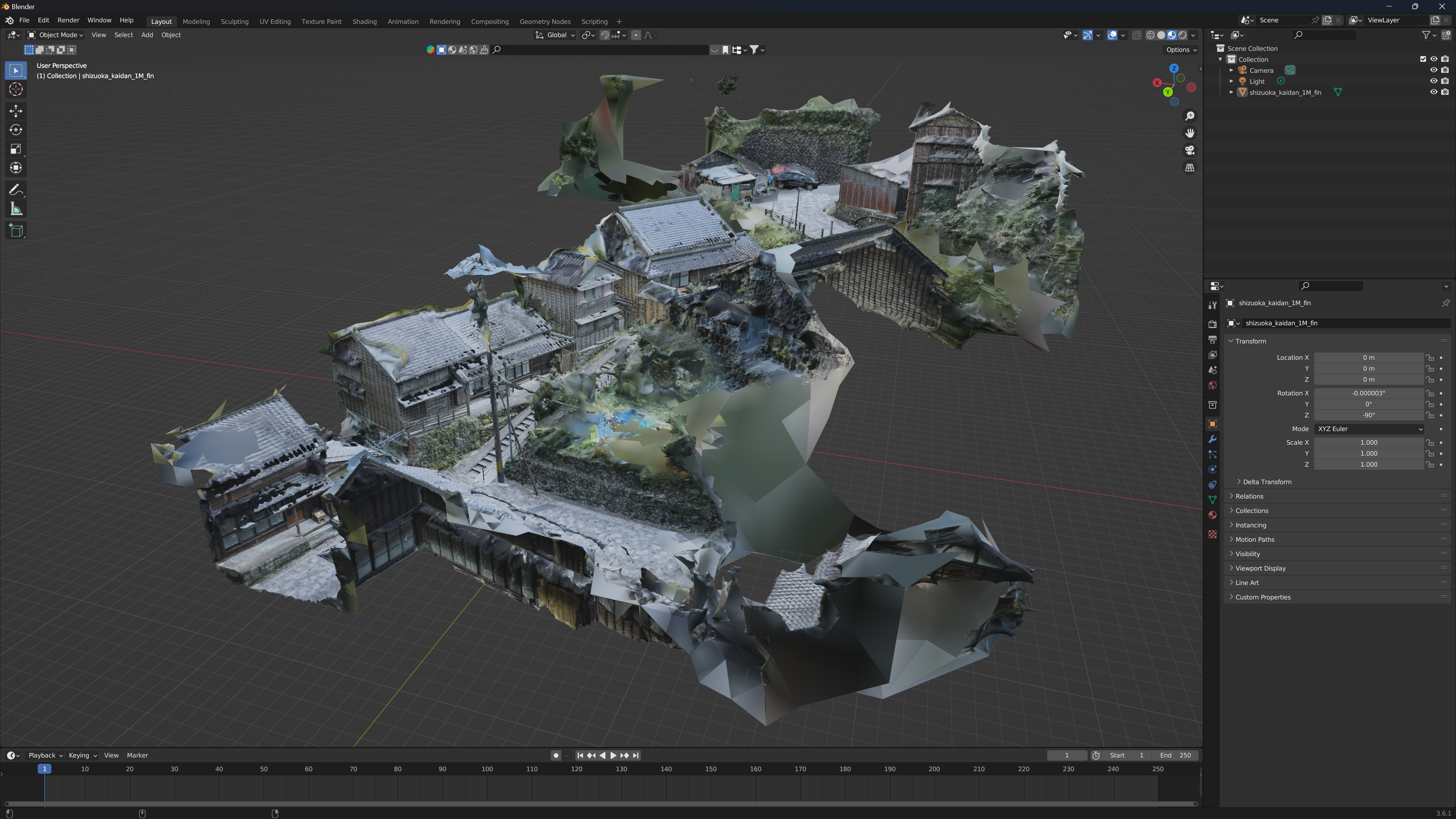
街並みの端のほうは違和感のある部分もありますが、建物を覆うような壁が消えたのでライティングに支障をきたすなどはないようなモデルができたかと思います。
ここで1点注意としては、フォトグラメトリで生成されるメッシュは、かなり頂点や面の数が膨大でした。頂点数が1億を超えているなど。しかし、その規模のメッシュをBlenderに取り込むと、処理が遅くメッシュの修正に膨大な時間がかかったり、そもそもBlenderにimportすること自体ができなかったりします。そのため、Reality Capture上で先にメッシュをシンプル化しておくと良いかと思います。例えば頂点数を100万程度にするなどです。
3. テクスチャの生成
メッシュが生成できたら、3Dモデルに色を付けるために、テクスチャを付与します。
ちなみに、ステップ2でのメッシュ修正の時点で、色を付けていますが、Blenderでの作業をしやすくするために、色を付けたメッシュをBlenderでimportしています。そのため、実際の作業フロー上は、ステップ2~4を何回か往復することになるかもしれません。
ちなみに、ステップ2でのメッシュ修正の時点で、色を付けていますが、Blenderでの作業をしやすくするために、色を付けたメッシュをBlenderでimportしています。そのため、実際の作業フロー上は、ステップ2~4を何回か往復することになるかもしれません。
また今回は映像制作にあたり、メッシュ状態での表示 / 点群状態での表示を使い分けたため、テクスチャと頂点カラーの両者を付与しました。単純にメッシュ状態で表示したいだけであればテクスチャのみを付与すればよい気がします。
4. FBXなどの形式で3Dモデルとして出力する
最後にできあがったメッシュを3Dモデルとして出力します。Reality Captureでは、かなり網羅的に出力形式が選べるかと思います。今回はUE5でメッシュ表示するためにFBX、LiDAR Point Cloud Plugin[13]での点群表示のためにlasという2種類の形式で出力しました。
なお、Reality Captureでの作業は、3Dモデルを出力する前までの段階であれば無料です。3Dモデルとして保存する際に(おそらく入力として使用した写真データの解像度などに応じて)費用が計算されて、請求が発生します。
なので、自分で撮影した写真でフォトグラメトリを試してみる部分までは無料で行えます。
なので、自分で撮影した写真でフォトグラメトリを試してみる部分までは無料で行えます。
実際に制作した映像例
最後にフォトグラメトリにより生成した3DモデルをUE5上で設置し、制作した映像をご紹介します。
まず、UE5上での3Dモデルの見え方としては、下記のようになります。
まず、UE5上での3Dモデルの見え方としては、下記のようになります。



1番最初の3Dモデルは比較的広く人通りが多い場所であったため、撮影が難しく、ボコボコしていたり穴が空いている部分も多くなっています。このあたりは映像化する際にカメラ位置を調整し、なるべく気にならないような画角を探す必要がありました。
上記のようなモデルを使い、実際に制作した映像が下記です。
フォトグラメトリ用の撮影は、昼間 / 晴れ / 手持ちカメラという状況で行いましたが、それを3Dモデル化しUE5上で撮影を行ったことで、夜 / 雨 / ドローン視点のような状況の映像も作れました。
また、最後の映像のように点群として3Dモデル化した街並みを処理することで、非現実的な映像制作にも挑戦しました。
このように一度3Dモデル化すると、後から撮影時とは異なるシチュエーションや演出内容を試行錯誤できる点が非常に魅力的だなと感じました。
また、最後の映像のように点群として3Dモデル化した街並みを処理することで、非現実的な映像制作にも挑戦しました。
このように一度3Dモデル化すると、後から撮影時とは異なるシチュエーションや演出内容を試行錯誤できる点が非常に魅力的だなと感じました。
今回は、フォトグラメトリ用の撮影から、3Dモデル生成、それを活用したUE5によるフォトリアルな映像制作に至るまでのほぼ全行程について、初めてのことばかりでした。
撮影ノウハウや、生成された3Dモデルの修正、UE5での映像制作など、さらにスキルアップして今後の機会に活かせればと思っております。
撮影ノウハウや、生成された3Dモデルの修正、UE5での映像制作など、さらにスキルアップして今後の機会に活かせればと思っております。
<!—— SHARE ——>
//データサイエンティスト/AIエンジニア/ビジネスプラナー
小山田 圭佑
Keisuke Oyamada
==============
<‑‑
‑‑>



タグ一覧
#次世代メディアデータ基盤#メディアソリューション#TV視聴ログ#GPS位置情報データ#メディア・コンテンツ開発#レシピデータ#自然言語処理#音声処理#表情感情推定#脳波#画像生成#text2image#Diffusion Model#3Dモデリング#PIFu#Mixamo#音声合成#Zero-Shot learning#Multilingual TTS#最適化#イベント登壇#人工知能学会#Developers Summit#デブサミ#エモテク#TV番組分析#SNSデータ#声質変換#Voice Conversion#Retrieval-based Voice Changer#image to 3d#NeRF#Volume Rendering#3D Reconstruction#空中触覚デバイス#フォトグラメトリ#初音ミク#AIラッパー#雑誌データ分析